L'approche de la force brute serait d'essayer d'ajouter des lettres à chaque index disponibles à l'aide d'une recherche en profondeur d'abord. Donc, en commençant par 'a', il y a deux endroits où vous pouvez ajouter une nouvelle lettre. Devant ou derrière le 'a', représenté par des points ci-dessous.
.a.
Si vous ajoutez un 't', il y a maintenant trois positions.
.a.t.
Vous pouvez essayer d'ajouter à chaque position disponible toutes les 26 lettres. Le dictionnaire dans ce cas peut être une simple hashtable. Si vous ajoutez un 'z' au milieu, vous obtenez 'azt' qui ne serait pas dans la hashtable donc vous ne continuez pas ce chemin dans la recherche.
Édition: Le graphique de Nick Johnson m'a rendu curieux de savoir à quoi ressemblerait un graphique de tous les chemins maximaux. Il est un grand (1,6 Mo) l'image ici:
http://www.michaelfogleman.com/static/images/word_graph.png
Modifier: Voici une implémentation de Python. L'approche par force brute fonctionne réellement dans un laps de temps raisonnable (quelques secondes, selon la lettre de départ).
import heapq
letters = 'abcdefghijklmnopqrstuvwxyz'
def search(words, word, path):
path.append(word)
yield tuple(path)
for i in xrange(len(word)+1):
before, after = word[:i], word[i:]
for c in letters:
new_word = '%s%s%s' % (before, c, after)
if new_word in words:
for new_path in search(words, new_word, path):
yield new_path
path.pop()
def load(path):
result = set()
with open(path, 'r') as f:
for line in f:
word = line.lower().strip()
result.add(word)
return result
def find_top(paths, n):
gen = ((len(x), x) for x in paths)
return heapq.nlargest(n, gen)
if __name__ == '__main__':
words = load('TWL06.txt')
gen = search(words, 'b', [])
top = find_top(gen, 10)
for path in top:
print path
Bien sûr, il y aura beaucoup de liens dans la réponse. Ceci imprimera les N premiers résultats, mesurés par la longueur du mot final.
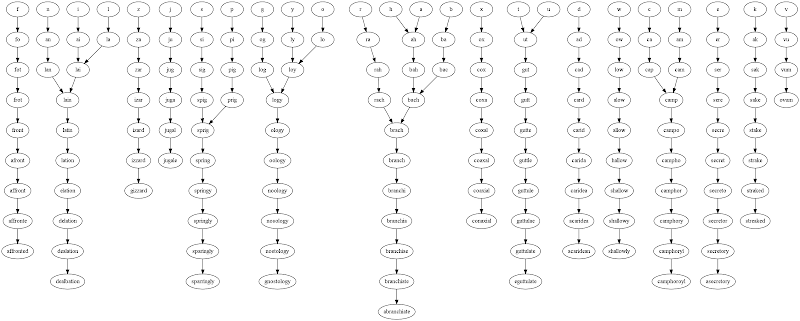
Sortie pour la lettre de début 'a', en utilisant le dictionnaire TWL06 Scrabble.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampeder', 'stampeders'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'estranges', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangers', 'stranglers'))
Et voici les résultats pour chaque lettre de départ. Bien sûr, une exception est faite que la lettre de début unique ne doit pas être dans le dictionnaire. Juste un mot de 2 lettres qui peut être formé avec.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(9, ('b', 'bo', 'bos', 'bods', 'bodes', 'bodies', 'boodies', 'bloodies', 'bloodiest'))
(1, ('c',))
(10, ('d', 'od', 'cod', 'coed', 'coped', 'comped', 'compted', 'competed', 'completed', 'complected'))
(10, ('e', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(9, ('f', 'fe', 'foe', 'fore', 'forge', 'forges', 'forgoes', 'forgoers', 'foregoers'))
(10, ('g', 'ag', 'tag', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(9, ('h', 'sh', 'she', 'shes', 'ashes', 'sashes', 'slashes', 'splashes', 'splashers'))
(11, ('i', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(7, ('j', 'jo', 'joy', 'joky', 'jokey', 'jockey', 'jockeys'))
(9, ('k', 'ki', 'kin', 'akin', 'takin', 'takins', 'takings', 'talkings', 'stalkings'))
(10, ('l', 'la', 'las', 'lass', 'lassi', 'lassis', 'lassies', 'glassies', 'glassines', 'glassiness'))
(10, ('m', 'ma', 'mas', 'mars', 'maras', 'madras', 'madrasa', 'madrassa', 'madrassas', 'madrassahs'))
(11, ('n', 'in', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(10, ('o', 'os', 'ose', 'rose', 'rouse', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(11, ('p', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(3, ('q', 'qi', 'qis'))
(10, ('r', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('s', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('t', 'ti', 'tin', 'ting', 'sting', 'sating', 'stating', 'estating', 'restating', 'restarting'))
(10, ('u', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(1, ('v',))
(9, ('w', 'we', 'wae', 'wake', 'wakes', 'wackes', 'wackest', 'wackiest', 'whackiest'))
(8, ('x', 'ax', 'max', 'maxi', 'maxim', 'maxima', 'maximal', 'maximals'))
(8, ('y', 'ye', 'tye', 'stye', 'styed', 'stayed', 'strayed', 'estrayed'))
(8, ('z', 'za', 'zoa', 'zona', 'zonae', 'zonate', 'zonated', 'ozonated'))
{kind=link}
Problème intéressant. Qu'avez-vous essayé jusqu'ici, et où êtes-vous coincé? –
Définir "dictionnaire de mots". Est-ce une table de hachage, un trie ou quoi? Si c'est un trie, une simple recherche DF fonctionnera. Est-ce un arbre de suffixe comme le suggèrent vos balises? – IVlad
Cela ressemble à un problème de devoirs, mal spécifié. –